Building Graph-Based Dataset Recommendation System
Introduction
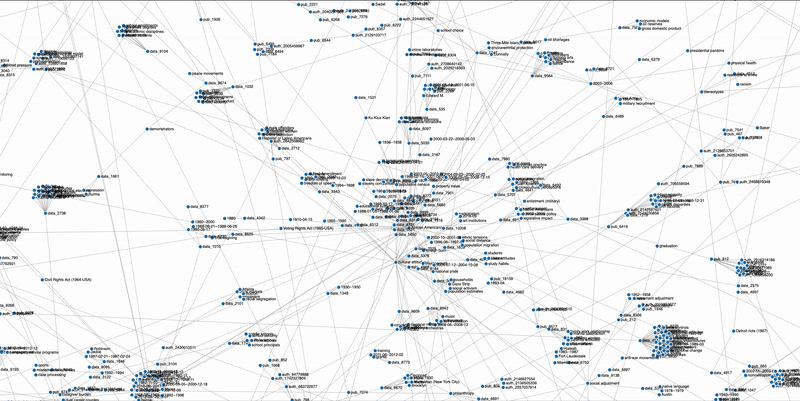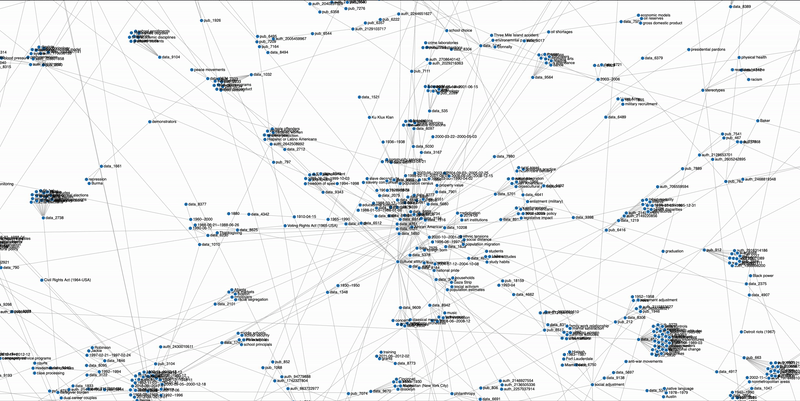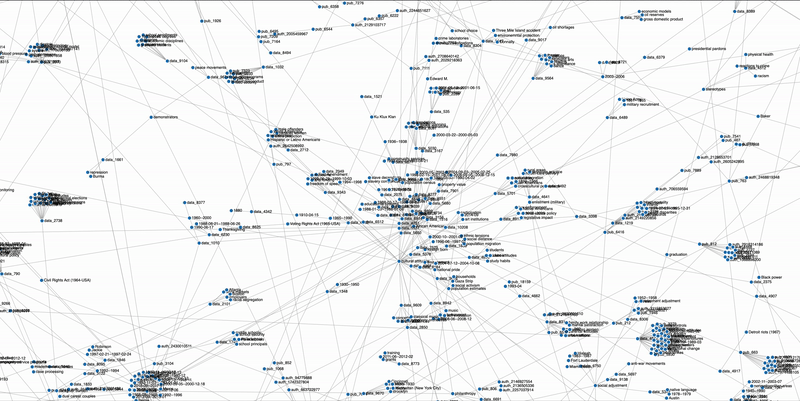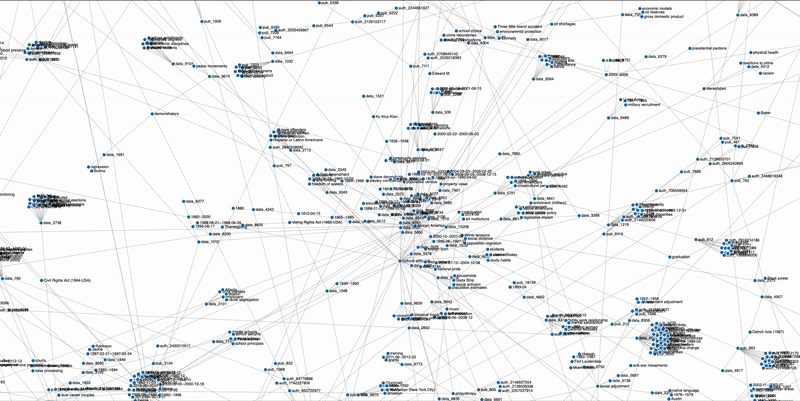
Exploring and finding existent research datasets and the relational network among themselves, between datasets and entities of interest such as research fields, paper titles, authors, and research methods are shown to be inefficient and the lack an integrated online platform that improves this process. This capstone project connects datasets with various entities in the academic research entities such as the publication papers that were used, the authors, the research field involved, as well as the subject terms given to the dataset. This heterogenous knowledge graph is built in order to improve user experience by building a dataset recommendation system based on the network.
Problem Statement
Great data go undiscovered and are undervalued
Time and resources are wasted redoing empirical work
No existing recommendation system for datasets
Our Goal
Build a dataset recommendation system to improve research efficiency.
Our Approach
Build a heterogenous knowledge graph network
Exploit information to develop a more well connected network
Use link prediction to measure connectivity between nodes
Data
1. Rich Context Competition Dataset
The Rich Context Competition held by Coleridge Initiative was with the intent to automate the discovery of research datasets, fields, and methods used in a publication paper. This project have used both the dataset used to train the model as well as the prediction output from the winner of the competition. These datasets include 3 main components
2. ICPSR Archive
TThe ICPSR Archive is considered an International Leader in Data Stewardship, maintaining a data archive of about 250,000 of research in the social and behavioral sciences. The ICPSR Bibliography of Data-related Literature is a searchable database that as of 2019 contains 80,000 citations of published and unpublished works resulting from analyses of data held in the ICPSR archive. This project is using about 15,000 publication papers and 10,348 dataset from the ICPSR archive in which we have extracted their metadata, such as subject terms, descriptions, titles, and DOI.
3. Microsoft Academic Graph Data
The Microsoft Academic Graph (MAG) currently has 218,951,661 papers with 239,743,363 authors, 664,149 topics, 4,384 conferences, 48,731 journals, and 25,511 institutions.
Demo
Conclusion
We built up the graph-based dataset recommendation system to improve research efficiency. The advantages of graph-based recommendation system include that it can leverage multiple types of entities and information, and it can generate results without requiring user activity history. We have utilized the available resources and improved upon our previous prototype network. Our preliminary network analysis has shown that we have successfully created a more connected network with deeper layers of entities, which results in more diverse sets of connections.
After successful efforts in creating more connected heterogeneous networks, we experiment on the network graphs and start to produce recommendation rankings. We conducted multiple recommendation ranking approaches and evaluated the results based on our predefined evaluation methods. The algorithms we used to calculate nodes similarity include Jaccard similarity, Cosine similarity, Hopcroft algorithm, and Adamic-Adar Index. Due to our evaluation metrics, the Cosine similarity algorithm has the best performance in terms of coverage and runtime.



